beanstalk
Table of contents
Overview
This post is strongly based on maxfang’s Simple and easy task queue - beanstalkd.
beanstalkd is a simple and fast distributed work queue system, the protocol
runs on TCP based on ASCII encoding. It was originally designed to reduce page
latency in high-volume web applications by performing time-consuming tasks
asynchronously in the background. It has the characteristics of simplicity,
light weight, and ease of use. It also supports the control of task priority,
delay/timeout resend, and client support in many language versions. These
advantages make it an ideal choice for various queue system scenarios. A common
choice for .
beanstalkd Advantages
- As introduced on his official website, simple&fast is very easy to use. It is suitable for introducing message queues but does not want to introduce heavy-duty MQ such as Kafka. The maintenance cost is low; at the same time, its performance is very high, and it can be covered in most scenarios.
- Support persistence
- Support message priority, topic, delayed message, message retry, etc.
- All mainstream language clients support it, and it can also be implemented by itself according to the beanstalkd protocol.
beanstalkd Insufficient
- Without maximum memory control, when there are too many business messages, the service may be unstable.
- The official does not provide a cluster failover solution (master-slave or sentry, etc.), you need to solve it yourself.
beanstalkd Key Concepts
job
Task, the basic unit in the queue, each job will have an id and priority. A bit similar to the concept of message in other message queues. However, the job has various states, which will be highlighted in the life cycle section below. Jobs are stored in tubes.
tube
Pipes are used to store jobs of the same type. A bit similar to the concept of topic in other message queues. beanstalkd implements multi-task queues through tubes. There can be multiple pipelines in beanstalkd, each pipeline has its own producer and consumer, and the pipelines do not affect each other.
producers
job producer. Put a job into a tube through the put command.
consumer
job consumer. Obtain the job through reserve, and change the status of the job through delete, release, and bury.
beanstalkd Lifecycle
As mentioned above, the job in beanstalkd has a state distinction. In the
entire life cycle, the job may have four states: READY, RESERVED, DELAYED,
BURIED.
Only READY jobs that are in state can be consumed. The figure below describes
the flow between the states.
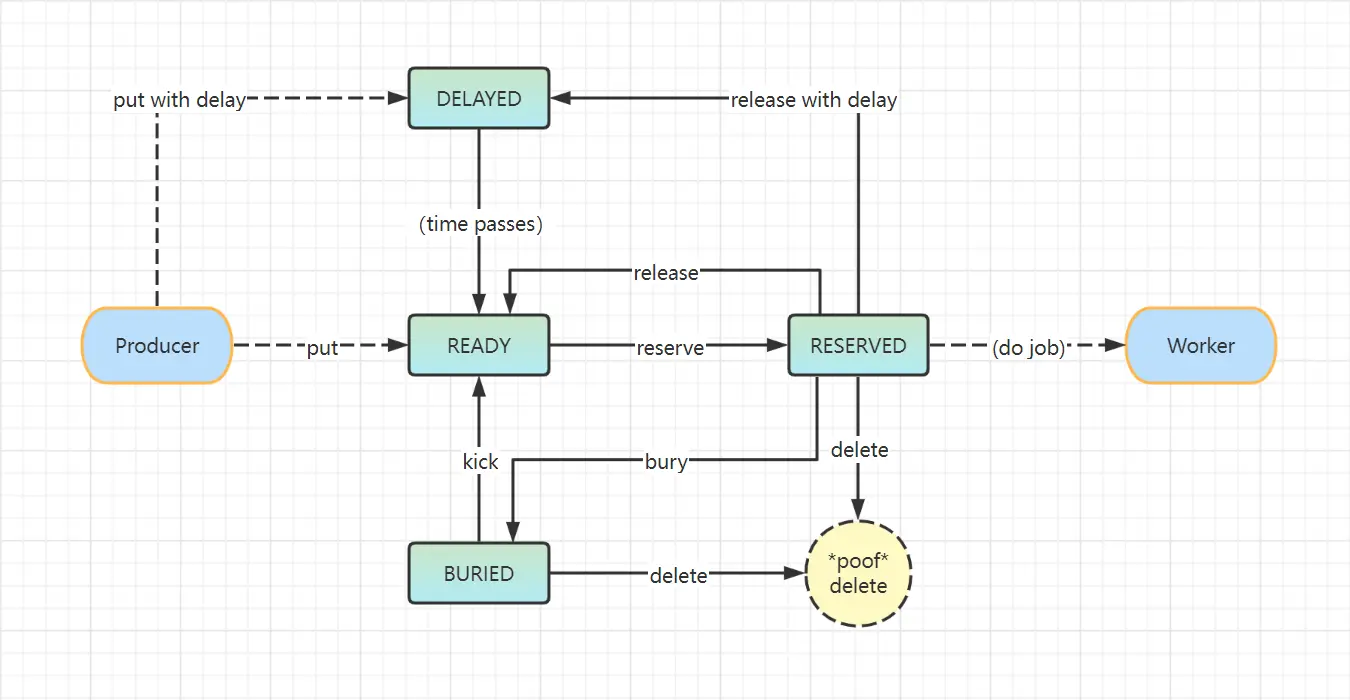
The producer has two ways when creating a job, put and put with delay (delayed task).
If the producer uses put to directly create a job, the job is in the READY
state, waiting for the consumer to process.
If the producer uses the put with delay method to create a job, the initial
state of the job is DELAYED, and it will change to READY after the delay time
has elapsed.
The jobs created by the above two methods will pass a TTR (timeout mechanism).
When the job is in the RESERVED state, the TTR will start counting down. put
back in the queue.
After the consumer obtains (reserves) a job in the READY state, the state of
the job will change to RESERVED. At this point, other consumers can no longer
operate the job. After the consumer completes the job, he can choose to delete,
release, or bury the operation.
delete, the job is deleted, cleared from beanstalkd, and cannot be obtained again in the future, and the life cycle ends.release, you can change the job to theREADYstate again, so that other consumers can continue to obtain and execute the job, or you can use release with delay to delay the operation, so that it will enter theDELAYEDstate first, and then becomeREADYafter the delay time.bury, you can sleep the job, and when needed, change the dormant job back to theREADYstate through the kick command, or directly delete the job in theBURIEDstate through delete.
A job in the BURIED state can return to the READY state through kick, or
delete the job through delete.
Why design this BURIED state?
Generally, we can use this state to catch exceptions.
For example, when executing a timeout or abnormal job, we can set it to the BURIED state.
This has several advantages:
- These abnormal jobs can be directly put back into the queue and restarted.
Try to affect normal queue consumption (these failed jobs are likely to fail
again). If there is no such
BURIEDstate, if we want to isolate separately, we will generally use a new tube to store these abnormal jobs separately, and use a separate consumer for consumption. This will not affect normal news consumption. Especially when the failure rate is relatively high, it will take up a lot of normal resources. - It is convenient for manual investigation. As mentioned above, you can set
the abnormal job to the
BURIEDstate, so that you can focus on this state during manual inspection.
beanstalkd Features
Persistence
The job and its status are recorded to the local file through the binlog. When beanstalkd restarts, the previous job status can be restored by reading the binlog.
Distributed
In the documentation of beanstalkd, it actually supports distributed. Its design idea is similar to that of Memcached. Each server of beanstalkd does not know the existence of each other. It realizes distribution through the client and obtains jobs from specific servers according to the tube name. Post an article dedicated to beanstalkd distribution, a distributed solution of Beanstalkd
Task Delay
Naturally supports delayed tasks, you can specify the delay time when creating a job, or after the job is processed, consumers can use release with delay to put the job into the queue again for delayed execution.
Task Priority
The job generated by the producer can be assigned a priority, which supports priorities from 0 to 2^32. The smaller the value, the higher the priority. The default priority is 1024. Jobs with high priority will be executed first by consumers.
Timeout Mechanism
In order to prevent a consumer from occupying a job for a long time but being
unable to complete it, the reserve operation of beanstalkd supports setting the
timeout time (TTR). If the consumer cannot send delete, release or bury
commands to change the job status within TTR, then beanstalkd will consider the
task processing failed and reset the job to READY status for consumption by
other consumers. If the consumer has predicted that the job may not be
completed within the TTR, it can send the touch command to make beanstalkd
recalculate the TTR.
Task Reserve
There is a BURIED state that can be used as a buffer. For specific features,
see the introduction of the BURIED state in the life cycle above.
Installation and Configuration
Take debian as an example to install beanstalkd:
apt-get install beanstalkd
The default configuration is in the file /etc/default/beanstalkd:
## Defaults for the beanstalkd init script, /etc/init.d/beanstalkd on
## Debian systems.
BEANSTALKD_LISTEN_ADDR=127.0.0.1
BEANSTALKD_LISTEN_PORT=11300
# You can use BEANSTALKD_EXTRA to pass additional options. See beanstalkd(1)
# for a list of the available options. Uncomment the following line for
# persistent job storage.
#BEANSTALKD_EXTRA="-b /var/lib/beanstalkd"
Services can be run through the beanstalkd command, and various parameters can be added. The format of the command is as follows:
# beanstalkd -h
Use: beanstalkd [OPTIONS]
Options:
-b DIR write-ahead log directory
-f MS fsync at most once every MS milliseconds (default is 50ms);
use -f0 for "always fsync"
-F never fsync
-l ADDR listen on address (default is 0.0.0.0)
-p PORT listen on port (default is 11300)
-u USER become user and group
-z BYTES set the maximum job size in bytes (default is 65535);
max allowed is 1073741824 bytes
-s BYTES set the size of each write-ahead log file (default is 10485760);
will be rounded up to a multiple of 4096 bytes
-v show version information
-V increase verbosity
-h show this help
Client
There are several clients. I just picked two for example:
Written in Rust
git clone https://github.com/schickling/beanstalkd-cli.git
cd beanstalkd-cli
cargo build --release
cp target/release/beanstalkd-cli ~/bin/
Usage:
$ beanstalkd-cli
Beanstalkd CLI
Usage:
beanstalkd-cli [options] put <message>
beanstalkd-cli [options] pop
beanstalkd-cli [options] monitor
beanstalkd-cli [options] stats [<key>]
beanstalkd-cli [(--help | --version)]
Commands:
put <message> Writes a message to the queue
pop Removes and prints the next message in the queue
monitor Live monitoring of the queue
stats [<key>] Prints all stats or stats for a specific key
Options:
-h, --host=<host> Hostname of the beanstalkd server [default: localhost]
-p, --port=<port> Port of the beanstalkd server [default: 11300]
-t, --tube=<tube> Tube to put/pop from - pop can use multiple tubes comma separated
--help Display this message
-v, --version Print version info and exit
Written in Go
git clone https://github.com/1xyz/yabean
cd yabean
go build
cp yabean ~/bin/
Usage:
$ yabean -h
usage: yabean [--version] [--addr=<addr>] <command> [<args>...]
options:
--addr=<addr> Beanstalkd Address [default: :11300].
-h, --help
The commands are:
del Delete a specific job.
kick Kick a buried job (Note: see reserve command to bury a job).
list List tubes.
peek Peek at a specific job.
peek-tube Peek into a specific tube.
put Put a job into a beanstalkd tube.
reserve Reserve a job from one or more tubes.
stats Retrieve serve statistics.
stats-job Retrieve statistics for a specific job.
stats-tube Retrieve statistics for a specific tube.